Problem C: Yanagi’s Comic
高校生の柳さんは、忍者マニアのボーイフレンドに「姫」と呼ばれる女の子である。 彼女は絵本が大好きで自作をするほどだが、今回はマンガの製作に挑戦するそうである。 彼女に無理やり絵本の手伝いをさせられてたあなたは、 今度はマンガ作りまで手伝うことになってしまった。
柳さんは自分の絵本を時々読みきかせている幼稚園の子供たちにもマンガを読ませたいことから、 マンガのコマに読む順番を振ろうと考えた。 もちろん、そのような仕事はアシスタントであるあなたが行うのである。
手早く仕事を終わらせたいあなたは、コマの位置からコマの読む順番を出力するプログラムを作ることにした。 それぞれのコマに対する読む順番を出力するプログラムを作成せよ。
この問題でのマンガは以下の規則に従う。
漫画は長方形の紙の上に描かれる。 紙の上辺をx軸、右側辺をy軸とする。 左方向をx軸の正の方向、 下方向をy軸の正の方向とする。 紙はすべてのコマが収まるのに十分な大きさを持っていると仮定せよ。 つまり、紙からコマがはみ出す領域は存在しない。 すべてのコマは1以上の面積を持っている。 すべてのコマの辺は、x軸、y軸のいずれかに平行である。 コマ同士、辺は共有することがあっても、共通の領域を持つことはない。
コマの集合Kに対する読み方を次の通りに定義する。
手順1 まだ読んでいないコマのうち、最も右のコマ、 複数ある場合、より上に位置するコマを始点のコマとし読む。 そのようなコマが存在しない場合、終了する。 手順1での、コマの位置とはコマの右上の頂点として考えて良い。
手順2 始点のコマの右下の頂点から線分を左側にページの下部の辺と平行に伸ばす。 このとき、他のコマの右側の側面にぶつかった場合、伸ばすのをやめる。 他のコマの辺上の場合は、伸ばしつづける。 紙の端まできたら伸ばすのをやめる。
手順3 手順2で伸ばした線分よりもコマの全ての領域が上に位置する
(辺と線分が重なっていても構わない)まだ読んでいないコマの集合をLとし、Lを読む。
手順4 1に戻る。
Input
入力データは複数のデータセットで構成されている。 入力の最後は0のみからなる行で示される。 そのデータは処理しなくてよい。
各データセットは以下の形式で与えらる。
n x01 y01 x11 y11 x02 y02 x12 y12 .... x0n y0n x1n y1n
データセット中のすべての数は整数である。 行中の整数の区切りはすべて空白一個である。 データセットの最初の行は一つの整数を含んでいる。 n はコマの数を表している。 x0i , y0i , x1i , y1i は i 番目のコマの隣り合わない二つの頂点を表している。
Constraints
0 < n < 10 (x0i , y0i ), ( x1i , y1i ) は( x0i != x1i かつ y0i != y1i )を満たす。 0 ≤ x0i , y0i , x1i , y1i ≤ 500
Output
各データセットに対して、出力は n 行で構成される。 i 行目に入力の i コマ目のコマを何番目に読むべきか を出力せよ。 また、各データセットの間には空行を出力せよ。
出力のフォーマット: num1 num2 . numi . numn
Sample input
4 0 0 100 60 0 60 50 90 50 60 100 90 0 90 100 120 6 0 0 100 40 0 40 50 70 50 40 100 60 50 60 100 80 0 70 50 120 50 80 100 120 0
Sample output
1 2 3 4 1 2 4 5 3 6
以下の画像は一つ目と二つ目のサンプルを表したものである。 灰色で示されるコマがすでに読んだコマである。 手順2で伸ばす線分を赤い直線で示している。画像中の番号は、入力で与えられるコマの順番を示す。
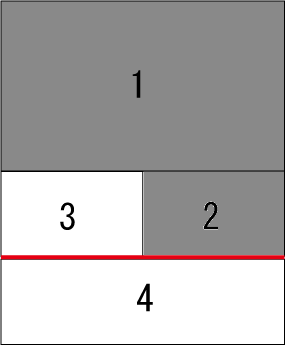
この画像は1つ目の入力例に対応している。
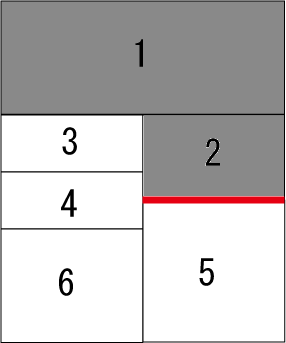
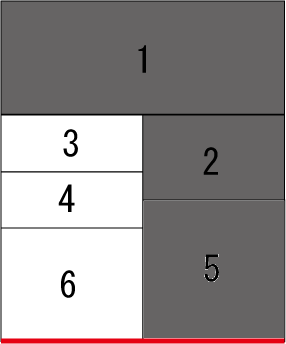
これらの画像は2つ目の入力例に対応している。